
Video Analytics System for Natural Language-Driven Surveillance
Problem: Traditional surveillance systems require manual rule-setting and lack adaptability to dynamic environments like ports or industrial sites. They often fail in challenging scenarios like occlusions, aerial views, or ambiguous human-object interactions.
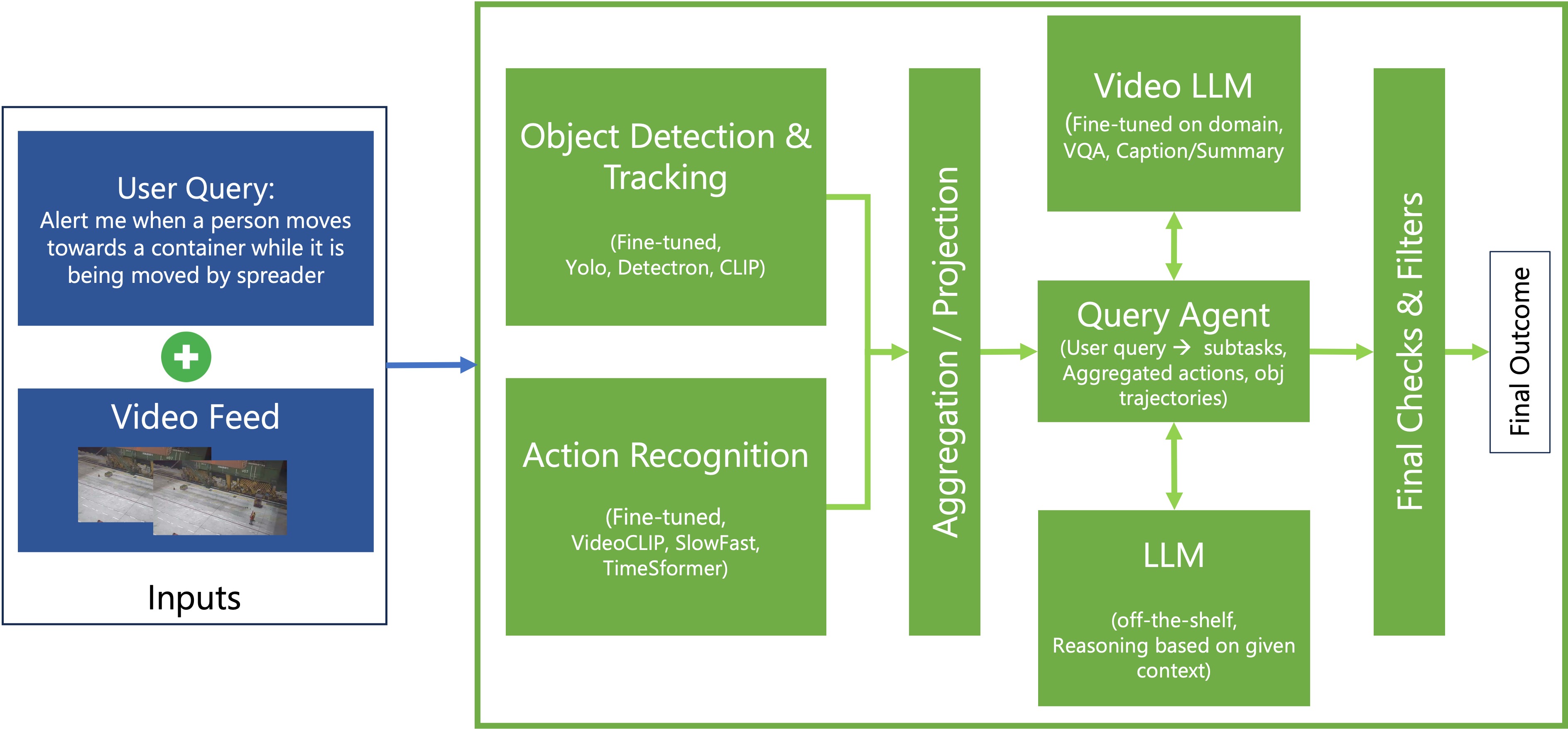
Solution & Architecture: This system enables natural language-driven video analysis using a pipeline of:
- Object Detection: YOLOv8, Detectron2, GroundingDINO, and OWL-ViT models fine-tuned on marine/industrial datasets.
- Tracking: DeepSORT for temporal tracking of people, containers, cranes, and spreaders.
- Action Recognition: Models like SlowFast and TimeSformer detect meaningful actions over N-frame windows.
- Video LLMs: InternVideo 2.5, Llava, and VideoLLaMA3 tested on port and domestic videos using context-aware prompts.
- Query Agent: Breaks down user queries into subtasks (e.g., proximity detection, container motion) and interprets results using GPT-4 or similar LLMs.
System Architecture:
Experiments & Observations: The team evaluated multiple VideoLLMs across scenarios (with/without blur/highlighting), revealing hallucination risks and gaps in temporal reasoning. Prompt engineering, object-aware attention, and subtask chaining significantly improved relevance.
Impact: The proposed architecture supports near-real-time analytics in industrial setups with minimal rule authoring. It offers an extensible framework for querying unstructured video via conversational input—helping ensure safety (e.g., worker too close to moving container) and increasing automation in surveillance tasks.